AWS with Python Project.
In this project, I used the AWS services to build the backend, python as main language, and postman as client.
The project is, to get the text of an invoice photo, saved it by date, and try to get the vendor name, total, iva 10%, and iva 5%,(those are the VAT values in my country, Paraguay) from the text extracted, then save those values in a CSV file, this file will be saved by date too, so if we send another photo and that photo belongs to the same year folder and month folder, it will add the extracted value in the same CSV file, at the end that file could be downloaded.
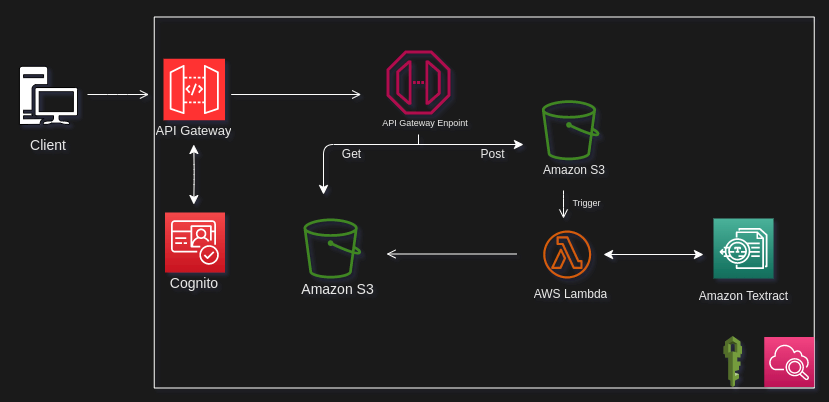
Here is the diagram that explains how the infrastructure looks like and I will try to explain how it works.
The client accesses the endpoints if it already has an account, this is managed by the Cognito service, which sends to the client an id_token through the URL.

So now we have the id_token, we can access the other endpoints, then every time we want to perform a request we have to send the token via the header

These are all endpoints we can access.

For example here, we’re sending an invoice photo, in the URL:
/invoice-control/{userId}/{year}/{month}/{item}

The userId is the identity ID of each user that manages Federated Identities. API Gateway receives that request and sends it to s3 as a proxy
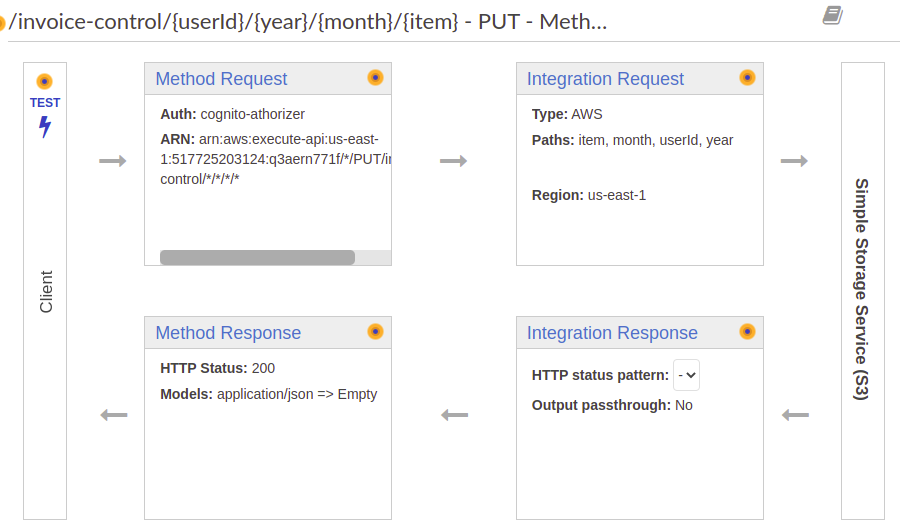
In integration request is where the URL path parameter is taken and saved the image in s3 via path override
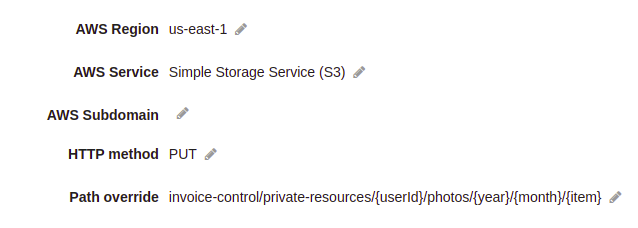
where:
invoice-control → the bucket
private-resource/ → the folder where the users will have their owns folders
userId/ → the user folder
photos/ → the folder of photos
year/ → the folder representing the year
month/ → the folder representing the month
The bucket has a trigger, which executes a lambda function, that contains the following code.
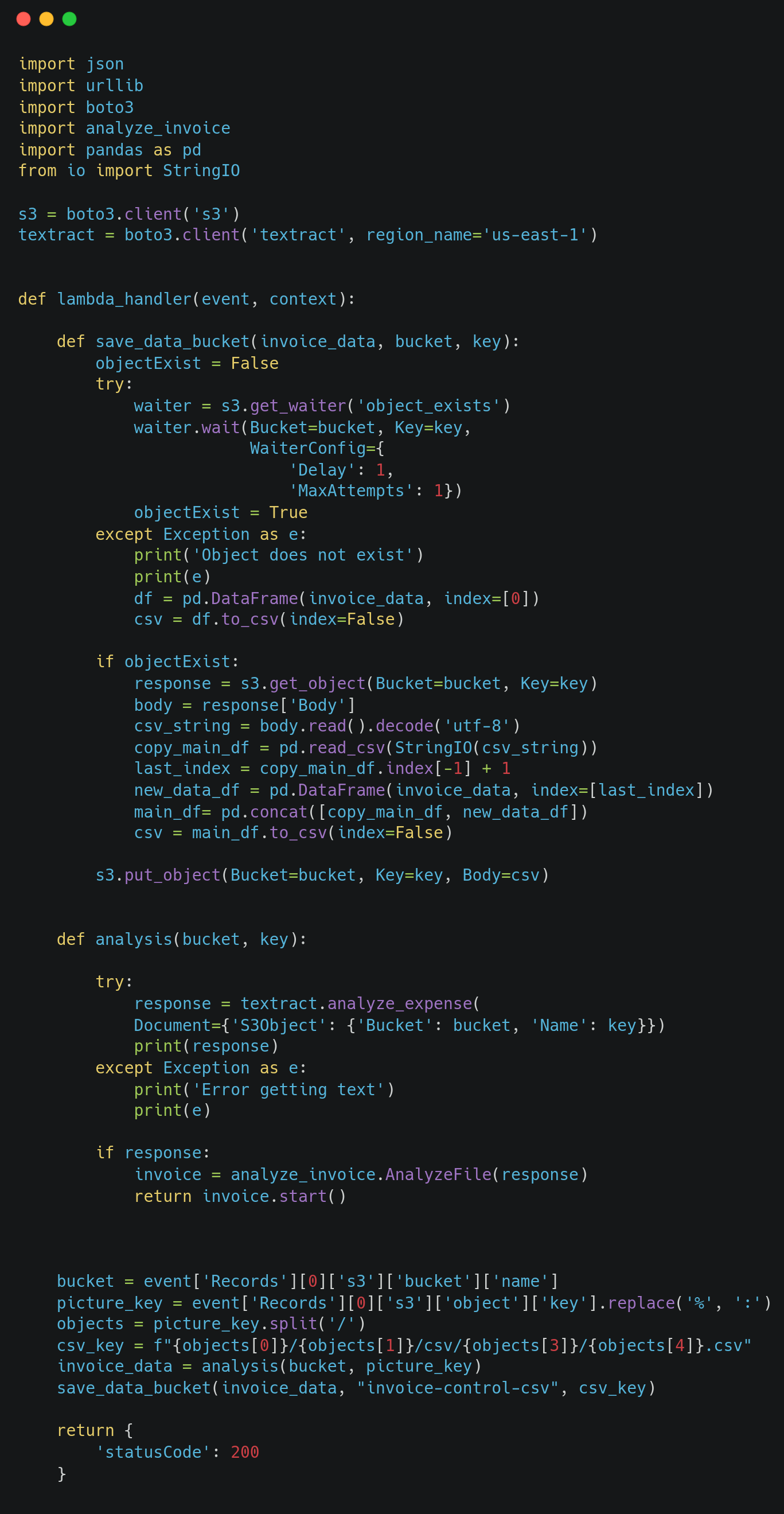
This code performs the actions below:
1) Analyze the invoice The analysis function uses Textract Service, it extracts text from invoices and pass the text to a class I’ve created, it’ll try to get the vendor name, IVA 5%, IVA10%, and the total expenses, and the class returns a dictionary with that data, to have all this data depends absolute on Textract, so in case where the text extracted doesn't have that data the class won’t able to obtained and instead the cell in the CSV will be blank. 2) Save the dictionary data as CSV in a bucket The save_data_bucket function checks if there’s already a CSV created, if there isn’t it uses pandas to create a CSV with the data, otherwise, if there is, it simply gets that file and overwrites it by adding the new data with pandas as well.
After the file is saved in the bucket:

*The lambda function that contains the code, uses 2 layers; pandas through its arn, and my class through a custom layer.
Now if we want to get the list of CSVs of the years, we can perform a request to: /invoice-control/{userId}/{year}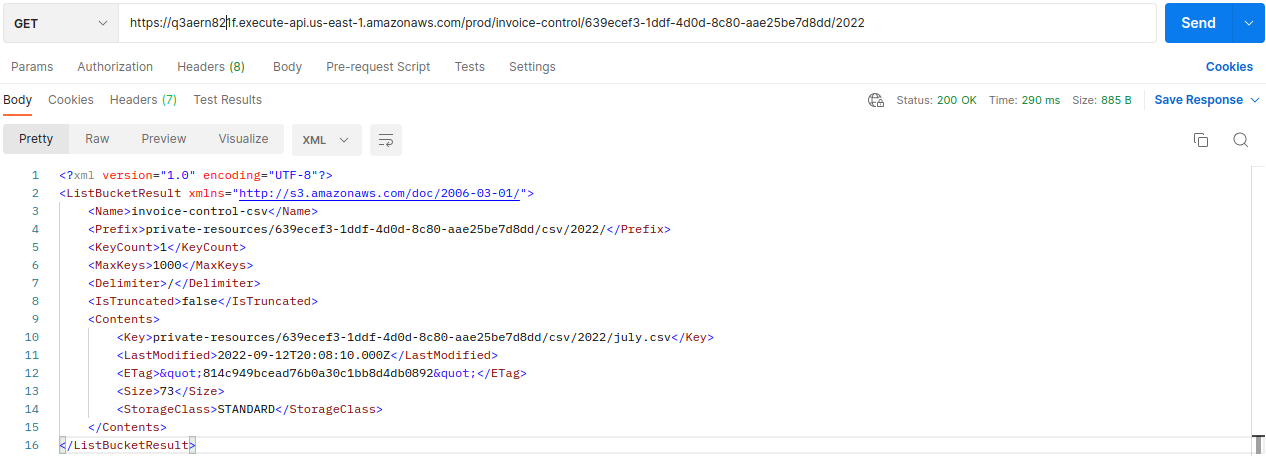
To have that kinda response we needed to specify the prefix and delimiter in the Integration request, API Gateway.

And finally, to download the CSV, we make a request to invoice-control/{userId}/{year}/{month}.csv API gateway and expects Accept: text/csv in the header to respond with that MIME Type

Postman has the option to send the request and download the response, and the file downloaded is:
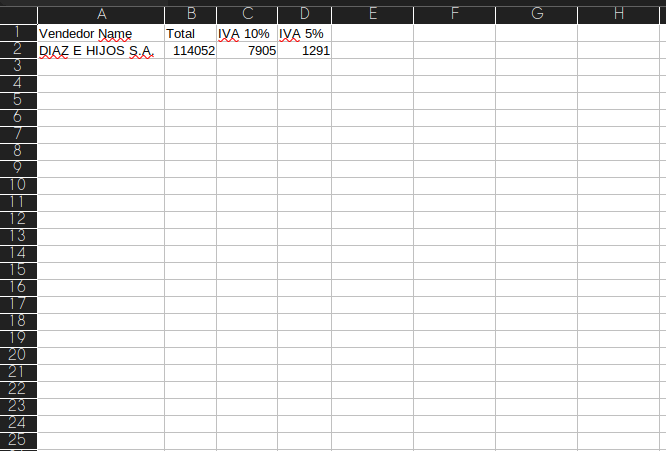
The AWS infrastructure that we have used in this project is used to read invoices and save the result as CSV, but we can do many other things with this infrastructure, the Textract service does not read only expenses, it also reads documents for example, or we can use another service that solves another problem.